Large language models (LLMs) are very popular these days. Most likely you have used tools such as ChatGPT or Claude. They are great, for many different tasks. But what they are not good at is working with your own, private data. Wouldn’t it be great if you could chat with a large language model about your own data, such as your Wikis?
In this blog post we are going to fine tune a foundational model with our own dataset and using LoRA and also show how to use the fine tuned model in a simple application. The focus is on the practical side of things, so that you can start fine tuning your own model.
RAG vs fine tuning
There are two popular approaches to tackle the issue of LLMs lacking specific domain knowledge: Retrieval-Augmented Generation (RAG) and fine-tuning. Currently, RAG solutions are more prevalent, but fine-tuning using Parameter Efficient Fine-Tuning (PEFT), specifically with Low-Rank Adaptation (LoRA), is gaining attention.
RAG
You can find a ton of information about RAG on the internet. Therefore, I will focus only on the basic idea. When using RAG, the domain specific data is looked up from a vector store and then used alongside the user chat message as context when interacting with the LLM.
In RAG, the LLM uses the retrieved context to generate more accurate responses without directly incorporating the data into its model weights.
- The user asks a question about a topic topic1
- The system vectorizes the user question about topic1 (this is where embeddings come into play)
- The system is looking up data related to topic1 from the vector store
- The system constructs the chat message to send to the LLM:
- the retrieved data from the vector store (your data)
- the question
- The LLM answers the question and uses the provided context information to do so, which creates an illusion of the LLM having knowledge about the data
Fine tuning
With RAG, we don’t do anything with the model, it’s the original model and the data is just passed alongside the request. Fine tuning on the other hand is the process of re-training the actual model with additional domain specific data, so we do change the model weights and ultimately have a new model that has the domain specific knowledge stored as part of the model.
Full parameter fine tuning is a very expensive process, specifically if we are using larger models. Therefore the most popular approach today is LoRA, or low rank adaptation. The idea is to use two low rank matrices to track the model weight changes instead of actually updating the original weights. You can find a ton of information about LoRA and the mathematical background on the internet, but I would like to keep this blog focused on the practical implementation.
What you should know though is that you can create two low rank matrices and multiply them to get a large matrix.
Let’s say the original weights are stored in a 100 x 100 matrix. We can now build two smaller matrices, for example of rank 5:
A=5 x 100 and B=100 x 5.
You might have guessed that multiplying A and B will result in a 100 x 100 matrix again.
Now in A and B, we only keep the weight changes that we learned during fine tuning. When we construct our final weights, the formula is:
W’ = W + (A x B).
In simple terms: we add the weight changes to the original model weights and with that get our fine tuned model W’ that we can use for inference.
Implementation
I hope above introduction didn’t scare you off. At the end of the day, it is good to understand the clever approach behind LoRA, but we want to get something practical done. So let’s focus now on the implementation.
What we are going to do
We are going to
- prepare a data set that represents our own data. We will use some silly example to show how this works
- Write some Python code to fine tune Meta’s opt-350m model and store the PEFT model
- Write a Python program that loads the new model and interacts with the model, just to see if it works
The idea is to get something working where we can actually see the results and understand what is going on, in a real-world scenario one would have more data to train on and use different hyper parameters and you may want a model that can answer your questions more generically.
Data preparation
We are using Hugging Face datasets library and keep our data local. The library can load data from various locations in various formats. We will use a JSON format.
To verify our model really learned from our data, let’s have the data being something the model wouldn’t know otherwise.
[
{
"text": "###Human: What are my cats names? ###Assistant: Your cats are named Frodo, Lutzi, Chili and Miro."
}
]The LLM is not intelligent in that sense, it just learns to reproduce the expected text. Therefore we split our data into two bits:
- What is the human saying / asking
- What should the system / assistent answer
To actually use the model we would send something like
"###Human: What are my cats names? ###Assistant:"And we want the model to complete the text based on what we trained it upon. That’s it.
We should have a training and an eval data set, so we store two files into a directory of our choice:
dataset/
train.json
eval.jsonFor our example the training data and the eval data is the same, as said, this is only an example you can then adjust to your needs.
The file content would be:
[
{
"text": "###Human: What are my cats names? ###Assistant: Your cats are named Frodo, Lutzi, Chili and Miro."
}
]You can of course add multiple rows. Experimentation is part of the game when fine tuning large language models, we will see that later.
Fine tuning
We will use the PEFT library to fine tune our model, this is the hardest part and I will try to focus on the minimal setup for the sake of this post. We are using the TRL library for this setup, it is relatively simple to use.
The TRL (Transformer Reinforcement Learning) library from Hugging Face is a helper library designed to simplify and streamline various machine learning tasks, particularly those related to fine-tuning large language models using reinforcement learning techniques.
The base model we use is Meta’s opt-350m.
Python environment
First we create a requirements.txt file that lists all the required libraries we need.
datasets==2.20.0
peft==0.11.1
rich==13.7.1
torch==2.3.1
tqdm==4.66.4
transformers==4.42.3
trl==0.9.6Then we create a new Python environment, where we can install the required dependencies.
# Create Python environment
python3 -m venv env
# Activate the environment (this is OS dependent, I use a macOS)
source env/bin/activate
# Install the dependencies
pip install -r requirements.txtNow we need some code, I tried to simplify it for this tutorial as much as I could. We create a new Python script named finetune.py.
import os
from datasets import load_dataset
from transformers import AutoTokenizer
from trl import SFTTrainer, SFTConfig
from peft import LoraConfig
# model configuration
model_name = "facebook/opt-350m"
output_dir = "output"
# training parameters
num_train_epochs = 50 # A high number of epochs, which may lead to overfitting; monitor validation metrics to prevent it
per_device_train_batch_size = 16
learning_rate = 5e-4 # A relatively high learning rate; intended for demonstration purposes to make weights adjust more significantly with a small dataset
# LoRA parameters
lora_r=8 # the rank of the matrices
lora_alpha=8 # scaling factor for the LoRA matrices, adjusts the impact of the adapted weights
lora_dropout=0.05 # dropout rate for LoRA layers, helping to regularize and prevent overfitting
lora_task_type='CAUSAL_LM'
# Load dataset
dataset = load_dataset('json', data_files={
'train': "dataset/train.json",
'test': "dataset/eval.json"
})
# Initialize tokenizer
tokenizer = AutoTokenizer.from_pretrained(model_name, use_fast=True)
tokenizer.pad_token = tokenizer.eos_token
# Configure training arguments
training_args = SFTConfig(
output_dir=output_dir,
num_train_epochs=num_train_epochs,
per_device_train_batch_size=per_device_train_batch_size,
learning_rate=learning_rate,
save_strategy="epoch",
evaluation_strategy="epoch",
logging_dir=os.path.join(output_dir, "logs"),
)
# LoRA configuration
peft_config = LoraConfig(
r=lora_r,
lora_alpha=lora_alpha,
lora_dropout=lora_dropout,
task_type=lora_task_type
)
# Initialize and run the trainer
trainer = SFTTrainer(
model=model_name,
args=training_args,
train_dataset=dataset['train'],
eval_dataset=dataset['test'],
dataset_text_field="text",
peft_config=peft_config,
tokenizer=tokenizer,
)
trainer.train()
trainer.save_model(output_dir)Note: The hyperparameters used here are for demonstration purposes. In practice, you should carefully tune these parameters based on your specific dataset and requirements to avoid issues like overfitting.
The code is actually quite simple.
- define the relevant parameters
- load the dataset
- construct an SFT trainer
- train the model and save the results
We can then run the code using the accelerate helper:
accelerate launch --num_processes 8 --mixed_precision 'fp16' train.pyand watch the machine fine tune our model, it shouldn’t take long with our example configuration.
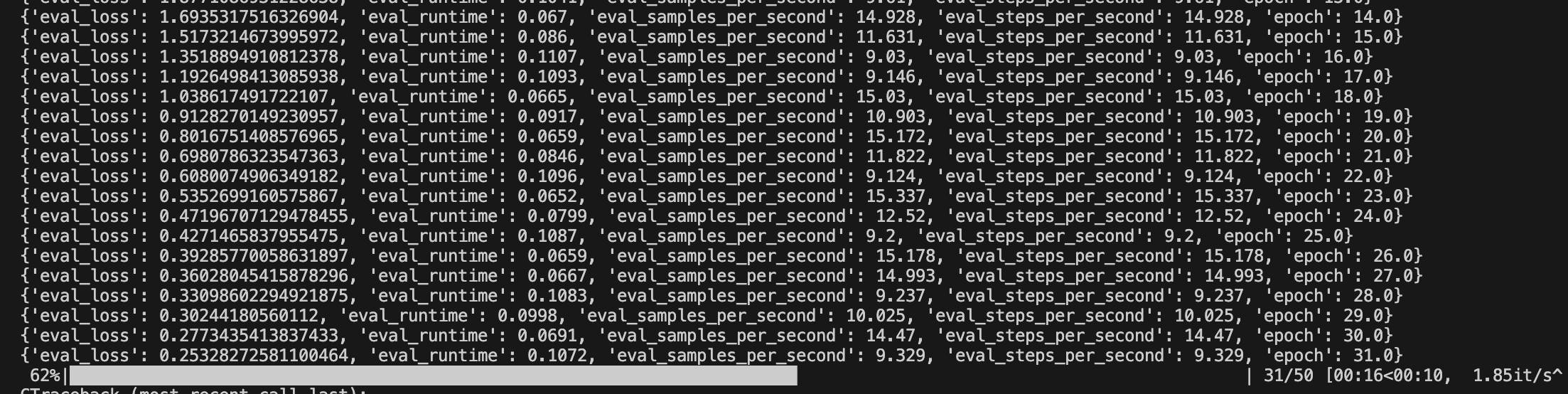
Using the model
When training was successful, we can test the new model. For this we can create a new Python script test.py
import torch
from transformers import AutoModelForCausalLM, AutoTokenizer, pipeline
from peft import PeftModel
# Model configuration
base_model_name = "facebook/opt-350m"
fine_tuned_model = "output"
device = "mps" if torch.backends.mps.is_available() else "cpu"
# Load the base model and apply fine-tuning
base_model = AutoModelForCausalLM.from_pretrained(base_model_name, device_map=device)
model = PeftModel.from_pretrained(base_model, fine_tuned_model).merge_and_unload()
# Set up tokenizer
tokenizer = AutoTokenizer.from_pretrained(base_model_name)
tokenizer.pad_token = tokenizer.eos_token
# Create text generation pipeline
generator = pipeline("text-generation", model=model, tokenizer=tokenizer, max_length=200)
# Generate text
prompt = "###Human: My cats names? ###Assistant:"
result = generator(prompt)[0]['generated_text']
print(result)Run this using the Python interpreter and we should see some results like this, so the model obviously learned from our data and we got our first fine tuned model.
Please note I’m running on macOS, therefore I use the “mps” backend, you may want to switch to cuda if you are having an NVIDIA GPU. I also had to configure the MPS fallback:
export PYTORCH_ENABLE_MPS_FALLBACK=1
python3 test.py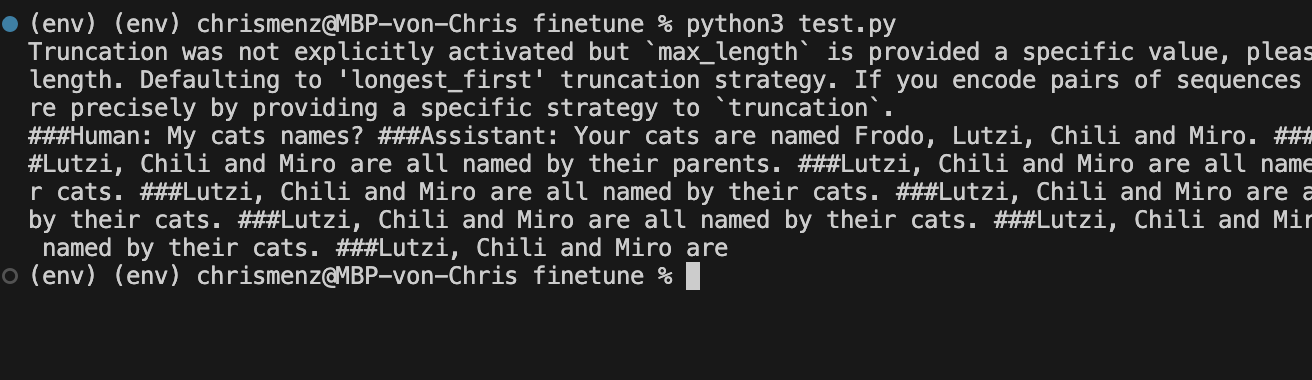
Conclusion
This is far away from a perfect configuration and setup, the model is not really useful as such, but I wanted to share this simple setup so that you can get started with less pain. Don’t use this for larger data sets, specifically the hyper-parameters are only for demonstration purposes, adjust them and experiment with larger datasets. Happy fine-tuning!